
1、編程方式
Hadoop的MapReduce在計算數據時,計算過程必須要轉化為Map和Reduce兩個過程,從而難以描述復雜的數據處理過程;而Spark的計算模型不局限于Map和Reduce操作,還提供了多種數據集的操作類型,編程模型比MapReduce更加靈活。
2、數據存儲
Hadoop的 MapReduce進行計算時,每次產生的中間結果都是存儲在本地磁盤中;而
Spark在計算時產生的中間結果存儲在內存中。
3、數據處理
Hadoop在每次執行數據處理時,都需要從磁盤中加載數據,導致磁盤的I/O開銷較大;而Spark在執行數據處理時,只需要將數據加載到內存中,之后直接在內存中加載中間結果數據集即可,減少了磁盤的1O開銷。
4、數據容錯
MapReduce計算的中間結果數據保存在磁盤中,并且 Hadoop框架底層實現了備份機制,從而保證了數據容錯;同樣 Spark RDD實現了基于 Lineage的容錯機制和設置檢查點的容錯機制,彌補了數據在內存處理時斷電丟失的問題。
在Spark與Hadoop的性能對比中,較為明顯的缺陷是Hadoop中的MapReduce計算延遲較高,無法勝任當下爆發式的數據增長所要求的實時、快速計算的需求。
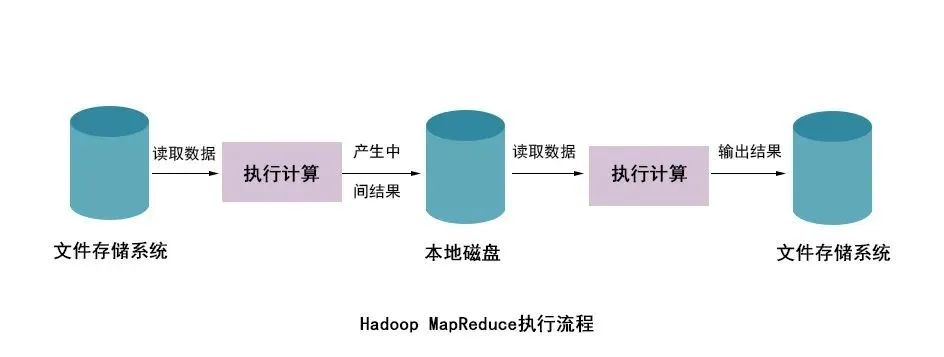
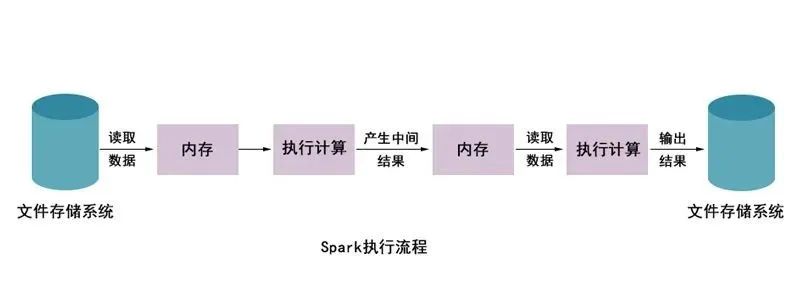
從上圖可以看出,使用Hadoop MapReduce進行計算時,每次計算產生的中間結果都需要從磁盤中讀取并寫入,大大增加了磁盤的I/O開銷,而使用Spark進行計算時,需要先將磁盤中的數據讀取到內存中,產生的數據不再寫入磁盤,直接在內存中迭代處理,這樣就避免了從磁盤中頻繁讀取數據造成的不必要開銷。通過官方計算測試,Hadoop與Spark執行邏輯回歸所需的時間對比,如圖所示。
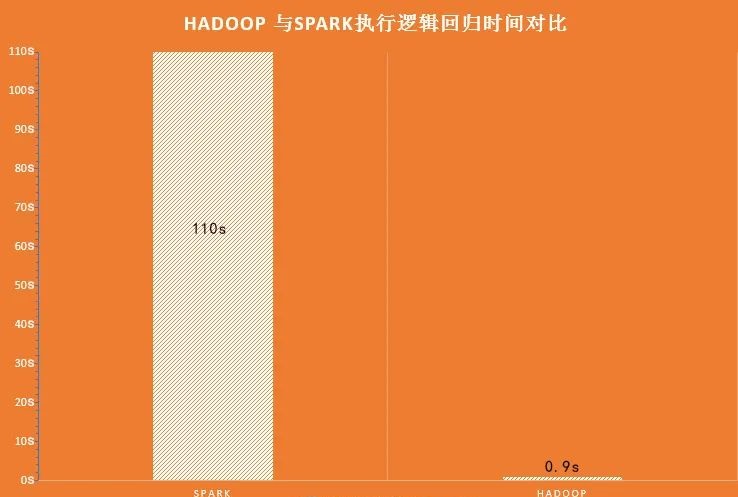
?從上圖可以看出,Hadoop與Spark執行的所需時間相差超過100倍。












